And there is now a MOAR TWEETZ section at the bottom to keep everybody zombiescrolling forever?
3 Likes
If you are unable to use the pain, you can schedule using out web site at …
ERROR! FAILED TO LOG IN!
ERROR! FAILED TO LOG IN!
TOO MANY FAILED LOGIN ATTEMPTS, ACCOUNT LOCKED!
No explanation of what the error was.
3 Likes
I think recent Winders authentication updates added a “suspicious use” case which uses bad logic to deny logins and single-sign-on. As one might expect from a bunch of clowns re-implementing the wheel.
3 Likes
Watching Super Tuesday coverage on PBS, through the YouTube live streams
( with mpv, not the YT website )
I’ve been watching my data usage, and even the low-res version of the stream was using like 500 kB/s which was ridiculous
Then I noticed there were two different entries
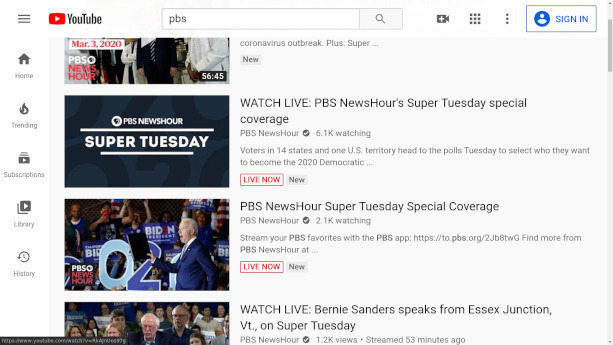
They’re both streaming the same thing, at the same resolutions
@640x360 the upper entry is 500 kB/s while the lower entry is 100 kB/s 
3 Likes
Census website lacks–
accessibility contact info.
accessible FAQ
accessible instructions.
The FAQ and instructions load as modals, and can’t load in their own tabs. They scroll on their own without scrolling the rest of the page, so it can be important to be able to read them in their own tabs and avoid the migraines. They aren’t readable with tools such as Reader View.
5 Likes
This was on mobile, but I went to census.gov and there was an accessibility link at the very bottom of the page that went to a document with a bunch of Section 508 information. Even in Trumpworld I’d be surprised to see those regs get ignored on a federal website.
Here’s the link in case you’re having trouble reaching it:
https://www.census.gov/about/policies/privacy/privacy-policy.html#accessibility
(I will say the “Is this page helpful” pop up on the bottom right corner of every page is super obnoxious.)
4 Likes
Ah, the completely non-obvious “privacy policy” link at the bottom goes to the same page I linked to before. I’m with you - that page is a disaster of accessible web design.
4 Likes
Encouraging use of “ease” in animation; “ease in-out” is one of my migraine triggers:
1 Like
So Ghostscript has the annoying habit of removing text from pdfs.
First, they ask me to reopen a bug if it persists. So I do. Then they tell me I shouldn’t have reopened the bug, they close it and explain I should open a new bug. So I do. Then they tell me it’s not a bug, because they don’t mind stripping useless text. Then they explain that they aren’t going to work on this whole class of bugs, because they don’t consider them bugs. Yeah, I get that pdf was designed as a prnting format, but it’s widely used for articles and ebooks, so readability, including searchability, navigibility, and for some screen reader compatibility, matters.
4 Likes
Has anyone else browsing with Firefox v 74.0 (on Win10) had a tab suddenly open up claiming an update for HTTPS Everywhere? Seemed suspicious, considering what it’s supposed to do.
2 Likes
One of my machines has that configuration and I have NOT seen that behavior, even when VPNed into the US via a California endpoint.
4 Likes
So I am trying to split an odt file so I can load each chapter into Calibre, and keep track of completeness, needed improvements, etc. there.
The standard instructions are to File > Send > Create Master Document and toss the odm file. Well, those don’t work. Anything before the 1st chapter heading doesn’t get its own odt file, and gets thrown away. Each chapter gets what’s labelled an odt file, but doesn’t open properly. I managed to repair them in Finder, load one into Calibre, and again, it doesn’t open properly. I don’t know what’s going wrong…
1 Like
No, it is not “fundamental to the idea of computing” that, at times, one or another program will jump to the fore, without my bidding.
And if I’ve clicked one one window, and started typing, not seeing the screen because I’m busy typing, if another program jumpts to the fore, I may end up typing in the wrong window because of the “fundamental” bad ui.
5 Likes
I finally actually tried to use use this shit show of a site today. What a master class in bad web design.
I stepped away from my computer for a few minutes and my session timed out and I had to start all over from the beginning. In Safari it kept randomly erroring and making me start from the beginning so I had to use Chrome.
Good grief.
3 Likes
Yes, but you can get the settings you want:
4 Likes
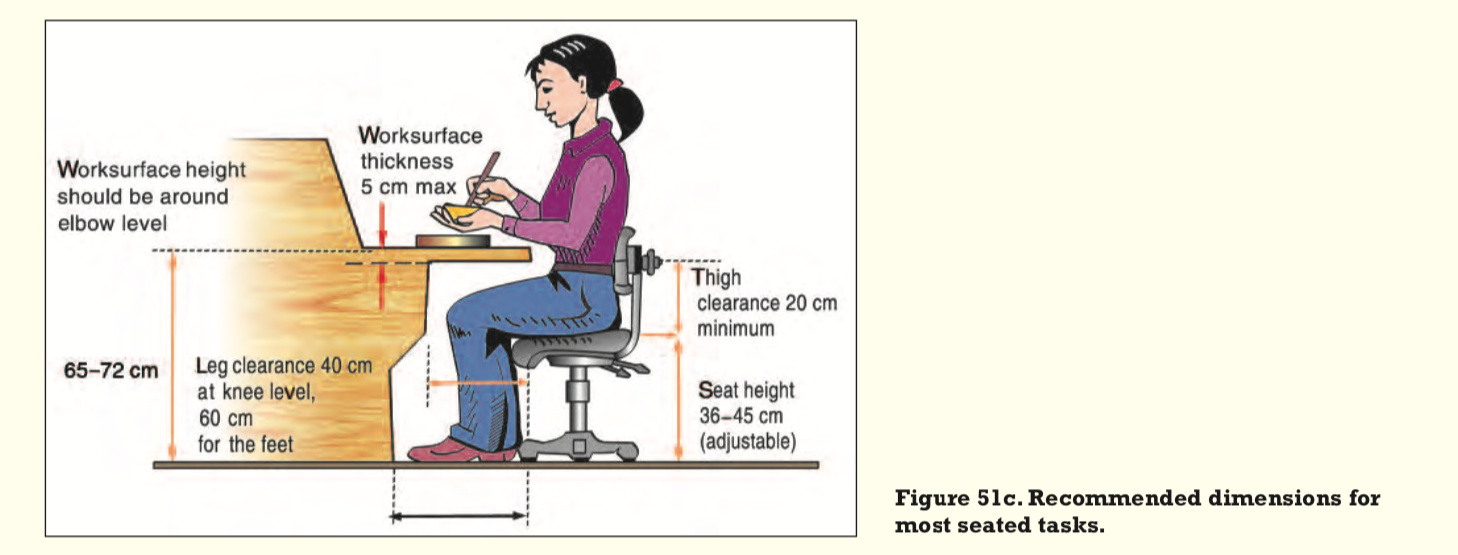
Do they assume everyone is at least 175 cm/69 inches?
Because they assume sitting elbow height is at least 65 cm…
I’m about average at around 165 cm/65 inches. And assuming a properly-sized chair, my sitting elbow height is about 60 cm.
from p. 109 here: https://www.ilo.org/global/topics/safety-and-health-at-work/resources-library/publications/WCMS_178593/lang--en/index.htm
4 Likes
I’ve found that a lot of my pdf problems are because of layered dfs designed for Acrobat Reader.
I can’t use Acrobat Reader, because it uses smooth scrolling, my Kindle can’t run it, and I have yet to find a way to strip out extra layers and export a more readable version. Most advice to remove a layer is actually to merge all layers.
Workaround:
-
Identify problem layers using PDFStudio Viewer. (Acrobat Reader could also work, depending.)
-
Duplicate the source pdf. Open it with TextEdit. (Another text editor could also work.)
-
Search for OCProperties. This will list numerical codes under OFF, ON, or other settings, with 0 R after each number.
-
Search for Name(x) where x is one of the names of the problem groups from step 1. You should find a list with numbered objects.
-
Note which numbers correspond with which problem groups. Move the corresponding numbers and 0 R from the ON list to the OFF list.
-
Save.
-
Open.
It gets more complicated if you want to track down specific items to move between OFF and ON OCGs.
But… this doesn’t require specialized pdf editing software after all.
P.S. The output may not work well with Ghostscript, but it works well with k2pdfopt.
3 Likes
Twitter being Twitter.
4 Likes